虚拟机配置 GPU(直通模式)¶
本文将介绍如何在创建虚拟机时,配置 GPU 的前提条件。
配置虚拟机的 GPU 的重点是对 GPU Operator 进行配置,以便在工作节点上部署不同的软件组件, 具体取决于这些节点上配置运行的 GPU 工作负载。以下三个节点为例:
- controller-node-1 节点配置为运行容器。
- work-node-1 节点配置为运行具有直通 GPU 的虚拟机。
- work-node-2 节点配置为运行具有虚拟 vGPU 的虚拟机。
假设、限制和依赖性¶
工作节点可以运行 GPU 加速容器,也可以运行具有 GPU 直通的 GPU 加速 VM,或者具有 vGPU 的 GPU 加速 VM,但不能运行其中任何一个的组合。
- 集群管理员或开发人员需要提前了解集群情况,并正确标记节点以指示它们将运行的 GPU 工作负载类型。
- 运行具有 GPU 直通或 vGPU 的 GPU 加速 VM 的工作节点被假定为裸机,如果工作节点是虚拟机, 则需要在虚拟机平台上启用 GPU 直通功能,请向虚拟机平台提供商咨询。
- 不支持 Nvidia MIG 的 vGPU。
- GPU Operator 不会自动在 VM 中安装 GPU 驱动程序。
启用 IOMMU¶
为了启用GPU直通功能,集群节点需要开启IOMMU。请参考如何开启 IOMMU。 如果您的集群是在虚拟机上运行,请咨询您的虚拟机平台提供商。
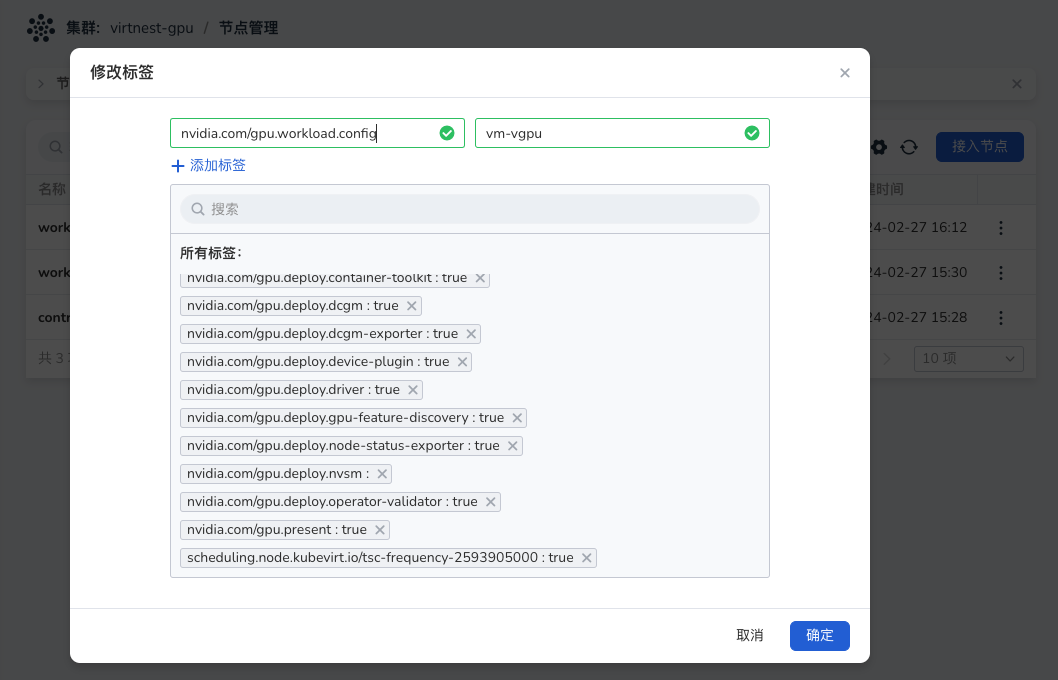
标记集群节点¶
进入 容器管理 ,选取您的工作集群,点击 节点管理 的操作栏 修改标签 ,为节点添加标签,每个节点只能有一种标签。
您可以为标签分配以下值:container、vm-passthrough 和 vm-vgpu。
安装 Nvidia Operator¶
-
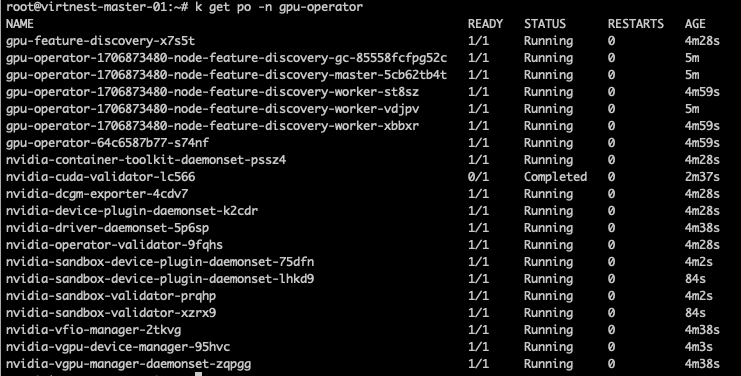
进入 容器管理 ,选取您的工作集群,点击 Helm 应用 -> Helm 模板 ,选择并安装 gpu-operator。 需要修改一些 yaml 中的相关字段。
gpu-operator.sandboxWorkloads.enabled=true gpu-operator.vfioManager.enabled=true gpu-operator.sandboxDevicePlugin.enabled=true gpu-operator.sandboxDevicePlugin.version=v1.2.4 # (1)! gpu-operator.toolkit.version=v1.14.3-ubuntu20.04- version 需要 >= v1.2.4
-
等待安装成功,如下图所示:
安装 virtnest-agent 并配置 CR¶
-
安装 virtnest-agent,参考安装 virtnest-agent。
-
将 vGPU 和 GPU 直通加入 Virtnest Kubevirt CR,以下示例是添加 vGPU 和 GPU 直通后的 部分关键 yaml:
spec: configuration: developerConfiguration: featureGates: - GPU - DisableMDEVConfiguration permittedHostDevices: # (1)! mediatedDevices: # (2)! - mdevNameSelector: GRID P4-1Q resourceName: nvidia.com /GRID_P4-1Q pciHostDevices: # (3)! - externalResourceProvider: true pciVendorSelector: 10DE:1BB3 resourceName: nvidia.com /GP104GL_TESLA_P4- 下面是需要填写的信息
- vGPU
- GPU 直通
-
在 kubevirt CR yaml 中,
permittedHostDevices用于导入 VM 设备,vGPU 需在其中添加 mediatedDevices,具体结构如下:- 设备名称
- GPU Operator 注册到节点的 vGPU 信息
-
GPU 直通需要在
permittedHostDevices下添加 pciHostDevices,具体结构如下:pciHostDevices: - externalResourceProvider: true # (1)! pciVendorSelector: 10DE:1BB3 # (2)! resourceName: nvidia.com/GP104GL_TESLA_P4 # (3)!- 默认不要更改
- 当前 pci 设备的 vednor id
- GPU Operator 注册到节点的 GPU 信息
-
获取 vGPU 信息示例(仅适用于 vGPU):在标记为
nvidia.com/gpu.workload.config=vm-gpu的节点(例如work-node-2)上查看节点信息, Capacity 中的nvidia.com/GRID_P4-1Q: 8表示可用 vGPU:Capacity: cpu: 64 devices.kubevirt.io/kvm: 1k devices.kubevirt.io/tun: 1k devices.kubevirt.io/vhost-net: 1k ephemeral-storage: 102626232Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 264010840Ki nvidia.com/GRID_P4-1Q : 8 pods: 110 Allocatable: cpu: 64 devices.kubevirt.io/kvm: 1k devices.kubevirt.io/tun: 1k devices.kubevirt.io/vhost-net: 1k ephemeral-storage: 94580335255 hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 263908440Ki nvidia.com/GRID_P4-1Q: 8 pods: 110那么 mdevNameSelector 应该是 “GRID P4-1Q”,resourceName 应该是 “GRID_P4-1Q”
-
获取 GPU 直通信息:在标记
nvidia.com/gpu.workload.config=vm-passthrough的 node 上(本文档示例 node 为 work-node-1), 查看 node 信息,Capacity 中nvidia.com/GP104GL_TESLA_P4: 2就是可用 vGPU:Capacity: cpu: 64 devices.kubevirt.io/kvm: 1k devices.kubevirt.io/tun: 1k devices.kubevirt.io/vhost-net: 1k ephemeral-storage: 102626232Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 264010840Ki nvidia.com/GP104GL_TESLA_P4: 2 pods: 110 Allocatable: cpu: 64 devices.kubevirt.io/kvm: 1k devices.kubevirt.io/tun: 1k devices.kubevirt.io/vhost-net: 1k ephemeral-storage: 94580335255 hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 263908440Ki nvidia.com/GP104GL_TESLA_P4: 2 pods: 110那么 resourceName 应该是 “GRID_P4-1Q”, 如何获取 pciVendorSelector 呢?通过 ssh 登录到 work-node-1 目标节点, 通过
lspci -nnk -d 10de:命令获取 Nvidia GPU PCI 信息,如下所示:红框所示即是 pciVendorSelector 信息。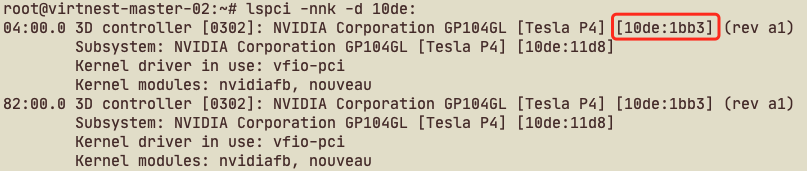
-
编辑 kubevirt CR 提示:如果同一型号 GPU 有多个,只需在 CR 中写入一个即可,无需列出每个 GPU。
spec: configuration: developerConfiguration: featureGates: - GPU - DisableMDEVConfiguration permittedHostDevices: # (1)! mediatedDevices: # (2)! - mdevNameSelector: GRID P4-1Q resourceName: nvidia.com/GRID_P4-1Q pciHostDevices: # (3)! - externalResourceProvider: true pciVendorSelector: 10DE:1BB3 resourceName: nvidia.com/GP104GL_TESLA_P4- 下面是需要填写的信息
- vGPU
- GPU 直通,上面的示例中 TEESLA P4 有两个 GPU,这里只需要注册一个即可
通过 YAML 创建 VM 并使用 GPU 加速¶
与普通虚拟机唯一的区别是在 devices 中添加 GPU 相关信息。
点击查看完整 YAML
apiVersion: kubevirt.io/v1
kind: VirtualMachine
metadata:
name: testvm-gpu1
namespace: default
spec:
dataVolumeTemplates:
- metadata:
creationTimestamp: null
name: systemdisk-testvm-gpu1
namespace: default
spec:
pvc:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
storageClassName: www
source:
registry:
url: docker://release-ci.daocloud.io/virtnest/system-images/debian-12-x86_64:v1
runStrategy: Manual
template:
metadata:
creationTimestamp: null
spec:
domain:
cpu:
cores: 1
sockets: 1
threads: 1
devices:
disks:
- bootOrder: 1
disk:
bus: virtio
name: systemdisk-testvm-gpu1
- disk:
bus: virtio
name: cloudinitdisk
gpus:
- deviceName: nvidia.com/GP104GL_TESLA_P4
name: gpu-0-0
- deviceName: nvidia.com/GP104GL_TESLA_P4
name: gpu-0-1
interfaces:
- masquerade: {}
name: default
machine:
type: q35
resources:
requests:
memory: 2Gi
networks:
- name: default
pod: {}
volumes:
- dataVolume:
name: systemdisk-testvm-gpu1
name: systemdisk-testvm-gpu1
- cloudInitNoCloud:
userDataBase64: I2Nsb3VkLWNvbmZpZwpzc2hfcHdhdXRoOiB0cnVlCmRpc2FibGVfcm9vdDogZmFsc2UKY2hwYXNzd2Q6IHsibGlzdCI6ICJyb290OmRhbmdlcm91cyIsIGV4cGlyZTogRmFsc2V9CgoKcnVuY21kOgogIC0gc2VkIC1pICIvI1w/UGVybWl0Um9vdExvZ2luL3MvXi4qJC9QZXJtaXRSb290TG9naW4geWVzL2ciIC9ldGMvc3NoL3NzaGRfY29uZmlnCiAgLSBzeXN0ZW1jdGwgcmVzdGFydCBzc2guc2VydmljZQ==
name: cloudinitdisk